
Need help with your Django project?
Check our django servicesTL;DR - Here is a demo of what we are going to achieve. Once you have this basic implementation you can use it in many different ways - in a View, to send notifications, etc.
Before we start
You should be familiar with:
Introduction
Almost every Web application needs to use some third-party software. The problem we usually have to deal with is that third-party apps, like every other app, can return an error. The following article is going to show you how to handle those problems in a nice and neat way in Django with Celery.
Base Example
First, you should install the third-party you want to use.
$ pip install third-party
The solution I am going to introduce to you is pretty generic so you could use it for every third-party app you need to integrate. Most of them come with a client you need to instantiate using an API key or something like that.
You actually use this client to communicate with the API of your third-party app. If there is no client interface in the library you can always create an abstract one and use it if needed.
Every third-party app has its own documentation and you have to follow it to be able to use their interface. Mostly, creating a new client instance is done this way:
from third_party import ThirdPartyClient
# Initialize client using api key
client = ThirdPartyClient(api_key=settings.THIRD_PARTY_API_KEY)!!! I strongly recommend to store data such as API keys and stuff like that into environment variables and using it from your settings files.
Now, once we’ve finished with the installation, we have to figure out how we are going to use our third-party application. As calling the server usually takes some time to get the response back, we should make calls asynchronously.
I am going to use Celery as it’s a stable and easy-to-use option for our needs. It requires a message queue and a great option here is RabbitMQ. You can check their documentation for the steps of installation if you haven’t set them up before.
As we are all set up, we are ready to go and write a task to take some information from our third-party.
from third_party import ThirdPartyClient
from celery import shared_task
from django.conf import settings
@shared_task
def fetch_data():
client = ThirdPartyClient(api_key=settings.THIRD_PARTY_API_KEY)
payload = client.fetch_data_method()
return payloadGoing back to Django
Everything is great at the moment – we have third-party app in our system which has a client and we communicate with it via async celery tasks. Now we have to go back to the synchronous MVC world of Django.
First, we need to make a model to store the data we fetch from the third-party app in order to be able to use it in our views and templates.
from django.db import models
class ThirdPartyDataStorage(models.Model):
# your fields here ...Since we already have where to store the fetched data, it’s about time to actually store it. This must happen in a specific moment – after we fetch it. As we do this via a celery task, we have to wait for the task to finish. Actually, there are 2 options:
- Do everything in one task – fetching data and creating a new model instance, but that is a bad practice because
one function would have to do a couple of things; - Create a second task to handle object creation and chain the two tasks.
Combine things together
Now we clearly know what we have to do:
- Create a task to fetch data from third-party app
- Create a task to save the fetched data in our database
- Connect everything together.
OK, let’s do the first two steps:
# in tasks.py
from third_party import ThirdPartyClient
from celery import shared_task
from django.conf import settings
from django.db import transaction
from .models import ThirdPartyDataStorage
@shared_task
def fetch_data():
client = ThirdPartyClient(api_key=settings.THIRD_PARTY_API_KEY)
fetched_data = client.fetch_data_method()
return fetched_data
@shared_task
@transaction.atomic # In case you have complex logic connected to DB transactions
def store_data(feched_data):
container = ThirdPartyDataStorage(**fetched_data)
container.save()
return container.idOur tasks are ready – now we have to chain them. This can be done easily using Celery’s chain().
To use it we can create a new task that just delays them:
from celery import shared_task, chain
@shared_task
def fetch_data_and_store_it():
t1 = fetch_data.s()
t2 = store_data.s()
return chain(t1, t2).delay()Data returned from the first task will be given to the second one as we use signatures (.s()). If you are not familiar with Celery I highly recommend that you read their documentation.
Use it
We’ve just come up with a single task from our tasks.py file which we are going to use – fetch_data_and_store_it().
The next question is: Where should I use it? In the view is probably the most natural answer you come up with and yes, you’re right.
In the MVC model (Django’s MTV), Controllers (Views) are responsible for generating the business logic. As your project gets bigger and bigger, you may need to use the task in different places – views, APIviews, etc.
In that case, you have to think of a better place of doing some more complicated business logic. For the needs of the current example, we will just use the task directly in a view but I recommend you to follow our blog for articles oriented on making your Django project nicely structured.
The example:
# in views.py
from django.shortcuts import render
from django.http import HttpResponseNotAllowed
from .tasks import fetch_data_and_store_it
def my_view(request):
if request.method == 'GET':
task = fetch_data_and_store_it.delay()
return render(request, 'index.html')
return HttpResponseNotAllowed(['GET'])That’s all – our structure is now clear. Let’s think of the main reason for this article – What do I do when an error occurs when I call a third-party app?
BaseErrorHandler
As we can see, our tasks are just python functions decorated with @shared_task (there are several other decorators in Celery that can do nearly the same).
What do these decorators really do? They just transform our function into an instance of Celery's Task class. Of course, as you expect, this class has all methods that we need if we want to plug into and make some custom logic.
What we are really interested in are the methods on_failure() & on_success() – the first one is called if an Exception is raised and the other one is called if there is no Exception.
We want to use the base Task class to handle third-party errors. Mostly all of the third-party apps raise an Exception when there is an error – you have messed up the API key (403 Permission Denied), a third-party server has some issues (500 Internal Server Error), and so on.
You may act differently depending on the errors, as Celery gives us the retry() but you always want to know when an error occurs.
Furthermore, if your system is used by some administration you should tell them when an error occurs – for example, an email is not sent or something like that. It’s not proper to let them search in celery.logs.
When we know all these stuff we are ready to use the OOP powers and make our BaseErrorHandler. You may’ve noticed that it’s Base so we have to make it abstract enough to use it in all third-party apps we want to integrate with. That’s why we are going to make a mixin:
class BaseErrorHandlerMixin:
def on_failure(self, exc, task_id, args, kwargs, einfo):
'''
exc – The exception raised by the task.
task_id – Unique id of the failed task.
args – Original arguments for the task that failed.
kwargs – Original keyword arguments for the task that failed.
'''
pass
def on_success(self, retval, task_id, args, kwargs):
'''
retval – The return value of the task.
task_id – Unique id of the executed task.
args – Original arguments for the executed task.
kwargs – Original keyword arguments for the executed task.
'''
passon_failure() method is run by the worker when the task fails. on_success() is run by the worker when the task is executed successfully. These methods are called synchronously before the serialization so there is no problem in having an Exception.
Now we have the main abstraction – let’s dive right in!
Inheriting Celery Tasks
As I’ve said before, every Celery task is actually an instance of Task class. Therefore, we can use it and inherit it.
This is easily done by changing the base of our tasks in the decorator we use. The problem is we’ve done just a mixin.
What is our new “base”? The answer is simple. We didn’t do a mixin to just be fancy – we want flexibility – now we can use it for every third-party task in our system.
The next step is to use the Task class:
# in tasks.py
from celery import Task
from .mixins import BaseErrorHandlerMixin
# Be careful with ordering the MRO
class ThirdPartyBaseTask(BaseErrorHandlerMixin, Task):
passIn our example we just have to add the following in the fetch_data() task decorator (you have to change the base of each task you want to track exceptions from – in our example store_data() task is not making any third-party calls or doing any complicated logic so we don’t need to change its base):
@shared_task(base=ThirdPartyBaseTask)
def fetch_data():
client = ThirdPartyCLient(api_key=settings.THIRD_PARTY_API_KEY)
fetched_data = client.fetch_data_method()
return fetched_dataNow we are ready to handle exceptions – let’s actually do it!
Handling errors
We have the architecture done and we just have to implement the logic to actually handle the errors.
First of all, we have to remember we are in the synchronous MVC world of Django. Yes, the option we have is to store the exceptions information in the database. This way we can use it to visualize it in a view and easily track all errors.
from django.db import models
class AsyncActionReport(models.Model):
PENDING = 'pending'
OK = 'ok'
FAILED = 'failed'
STATUS_CHOICES = (
(PENDING, 'pending'),
(OK, 'ok'),
(FAILED, 'failed')
)
status = models.CharField(max_length=7, choices=STATUS_CHOICES, default=PENDING)
error_message = models.TextField(null=True, blank=True)
error_traceback = models.TextField(null=True, blank=True)
def __str__(self):
return self.actionThis is the basic implementation of a model we want. Other fields you may want to add are:
- The user/admin that made the third-party call
- The action the user/admin did
- callback
- etc.
We have where to store the exceptions information so we have to use it now. Here is where our BaseErrorHandlerMixin comes in place.
Hook things together
Here is a simple diagram that shows what we are going to
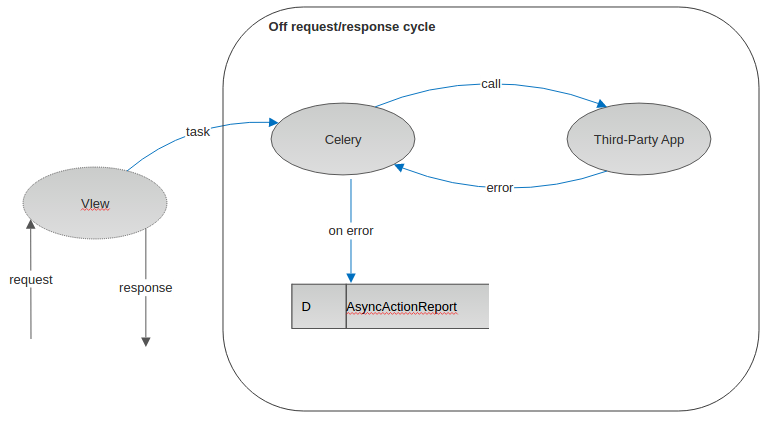
Since we are ready with the AsyncActionReport model, we have to create an instance of it. But how and where should we create it if we want to use it in the main task -> secondary tasks -> BaseErrorHandlerMixin?
Here comes the magic of Python! We are able to create the instance in the first position of the track (fetch_data_and_store_it() task) and to pass it upstairs. Just use the **kwargs!
In other words, once we create an AsyncActionReport instance, we can pass its id as a key-word argument in the secondary tasks we want to handle errors from (fetch_data() task).
This is how our tasks.py file finally looks:
# in tasks.py
from third_party import ThirdPartyClient
from celery import shared_task, Task, chain
from django.db import transaction
from django.conf import settings
from .models import ThirdPartyDataStorage, AsyncActionReport
from .mixins import BaseErrorHandlerMixin
class ThirdPartyBaseTask(BaseErrorHandlerMixin, Task):
pass
@shared_task(base=ThirdPartyBaseTask)
def fetch_data(**kwargs):
"""
Expected kwargs: 'async_action_report_id': AsyncActionReport.id.
This kwargs is going to be passed to the constructor of
the ThirdPartyBaseTask so we can handle the exceptions and store it
in the AsyncActionReport model.
"""
client = ThirdPartyClient(api_key=settings.THIRD_PARTY_API_KEY)
fetched_data = client.fetch_data_method()
return fetched_data
@shared_task
@transaction.atomic
def store_data(fetched_data):
container = ThirdPartyDataStorage(**fetched_data)
container.save()
return container.id
@shared_task
def fetch_data_and_store_it():
async_action_report = AsyncActionReport()
t1 = fetch_data.s(async_action_report_id=async_action_report.id)
t2 = store_data.s()
return chain(t1, t2).delay()Now we can add the actual logic for handling errors in the BaseErrorHandlerMixin
from .models import AsyncActionReport
class BaseErrorHandlerMixin:
def on_failure(self, exc, task_id, args, kwargs, einfo):
AsyncActionReport.objects.filter(id=kwargs['async_action_report_id'])\
.update(status=AsyncActionReport.FAILED,
error_message=str(exc),
error_traceback=einfo)
def on_success(self, retval, task_id, args, kwargs):
AsyncActionReport.objects.filter(id=kwargs['async_action_report_id'])\
.update(status=AsyncActionReport.OK)Conclusion
Everything is ready and we are now able to handle the errors from the third-party apps we use. As our project gets bigger and bigger we may need to use more and more third-party apps.
What I can recommend to you is to make a different app called integrations where you can add all logic connected with the integrations you use.
That’s how you can make your code easier to read and maintain and you can unittest it. And as I have just mentioned about “unittesting cellery tasks” you can look forward to an article about that soon.