
Need help with your Django project?
Check our django services
The last couple of months were pretty intense. Ever since ChatGPT 3.5 came out, and the world saw its potential, an avalanche of new AI tools came into existence.
After the initial existential crisis passed (as we discuss in HackCast S03E03 - How will AI change the way we build software?), we realized that the new set of AI-related tools can actually help us build better software & provide more value for our clients.
We see this happening in 2 major ways:
- Integrate those tools in our day-to-day job, by giving ChatGPT & Copilot an honest try, to really see if they can be helpful.
- Start navigating the existing ecosystem of new AI tools & libraries and evaluate potential use cases.
Point 2 is extremely important, since this can give us new ideas & new capabilities. And by having new ideas & capabilities, we can give more value to our clients.
So - lets explore a certain set of tools & ger our hands dirty!
What are we going to build?
For start, we are going to build something very simple:
- A Python CLI application.
- That indexes Django's documentation, while keeping relevant urls as sources (using OpenAI Embeddings API and Chroma as a vector database).
- That takes a question and tries to answer that question within the Django documentation context (again, using OpenAI's Embeddings & GPT APIs and Chroma as a vector database).
- And all of that, orchestrated by
langchain
So, effectively, we are building a "question answering over Django documentation" app.
Here's how our end result is supposed to look like:
We can ask a question:
How can we add a new unique field to an already existing model?
And get an answer:
To add a new unique field to an already existing model, you should add the field on your model with default and unique arguments, run the makemigrations command, generate two empty migration files for the same app by running makemigrations myapp --empty twice, and then add a RunPython or RunSQL operation to generate a unique value for each existing row. If the field is non-nullable, you should change unique=True to null=True and create an intermediary null field before adding the unique constraint.
https://docs.djangoproject.com/en/4.2/howto/writing-migrations/
https://docs.djangoproject.com/en/4.2/topics/db/models/
One more question:
How I can filter by a reverse relation?
And get an answer:
To filter by a reverse relation, use the lowercase name of the model in a lookup. For example, to retrieve all Blog objects which have at least one Entry whose headline contains 'Lennon', use the following code: Blog.objects.filter(entry__headline__contains="Lennon"). To override the default name of the Manager that returns QuerySets, set the related_name parameter in the ForeignKey definition.
https://docs.djangoproject.com/en/4.2/topics/db/queries/
https://docs.djangoproject.com/en/4.2/topics/db/models/
Question answering over documents?
If we want to leverage the power of a LLM, like ChatGPT, for data that it was not specifically trained for, we need to do something called "retrieval augmented generation".
When we ask a specific question about something from the Django documentation, we need to find that relevant part & pass it as a context to the LLM.
This is where the vector databases & embeddings come into play.
An embedding is a vector representation of a given text. Or to cite OpenAI's documentation:
📒 An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
On a high level, this is what we need to do:
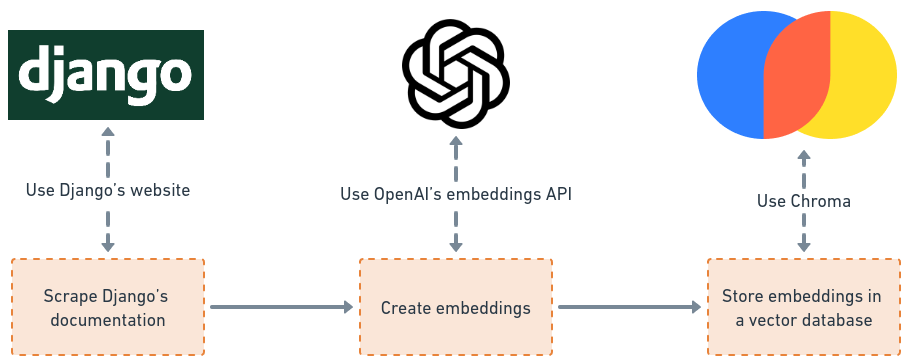
- We need to "scrape" the Django documentation & get the text out of it.
- We need to create embeddings for that text & store those embeddings in a vector database.
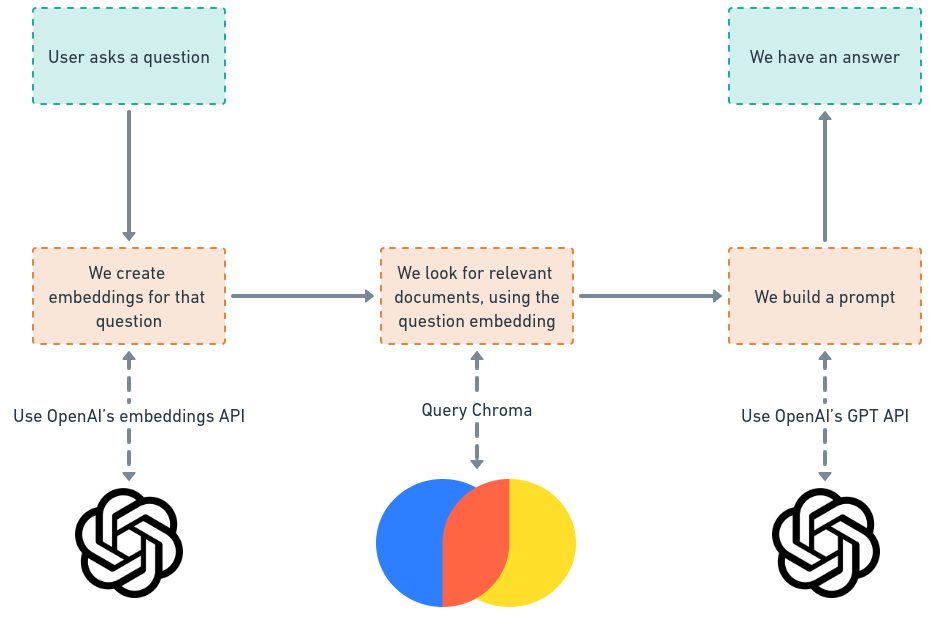
- Whenever we ask a question, we will generate the embedding for that question, and search within the vector database, for relevant parts of the Django documentation, that are "close" to our question.
- Finally, we will use the result returned from the vector database, to "prompt engineer" additional context for the LLM & let it do its magic.
And since we have the "bigger" picture of what we need to do, these are the specific tools that we are going to use:
- For scraping Django's documentation, we'll use things like
requestsandbs4. - For creating embeddings, we'll use OpenAI's Embeddings API.
- Our vector database is going to be Chroma (for storing embeddings, documents, sources & for doing relevant document searches).
- Everything is going to be glued together with langchain.
Lets express this with a diagram.
Preparing our data
Answering questions
For more on "question answering over docs", we highly recommend reading this - https://docs.langchain.com/docs/use-cases/qa-docs
Step 1 - Scraping Django's documentation
Now, this is quite straightforward & there are many ways to do it.
What we want to achieve is to get a unique list of urls, for all topics in the Django documentation.
Our strategy is going to be the following:
- Start from here - https://docs.djangoproject.com/en/4.2/contents/
- Get all links with
class="reference internal" - Since the links are given with relative parts (like
../intro/overview/) - we want to resolve that into absolute paths. - Since some of the links point to different anchors on same pages, we want to remove the so-called url fragments. For example, from
/en/4.2/intro/install/#install-django, remove#install-django - Finally, get a unique list of urls, which we are going to use later on.
We are going to need the following requirements:
pip install requests
pip install bs4Here's an example implementation (to be fair, the implementation can be done in a cleaner way, but it does the job.)
from pathlib import Path
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import requests
def django_docs_build_urls():
root_url = "https://docs.djangoproject.com/en/4.2/contents/"
root_response = requests.get(root_url)
root_html = root_response.content.decode("utf-8")
soup = BeautifulSoup(root_html, 'html.parser')
root_url_parts = urlparse(root_url)
root_links = soup.find_all("a", attrs={"class": "reference internal"})
result = set()
for root_link in root_links:
path = root_url_parts.path + root_link.get("href")
path = str(Path(path).resolve())
path = urlparse(path).path # remove the hashtag
url = f"{root_url_parts.scheme}://{root_url_parts.netloc}{path}"
if not url.endswith("/"):
url = url + "/"
result.add(url)
return list(result)Step 2 - Building our Chroma vector database
Okay, this is where the fun begins.
Even thought we can achieve this by simply using Chroma's Python SDK, we will leverage the power of langchain.
We will use 3 main features from langchain's Indexes:
- Document Loaders
- Text Splitters
- Vector Stores
We are going to need the following requirements:
pip install openai
pip install tiktoken
pip install python-dotenv
pip install langchain
pip install chromadbLets look at the code and then break it down:
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from dotenv import load_dotenv
load_dotenv()
CHROMA_DB_DIRECTORY = "chroma_db/ask_django_docs"
def build_database():
# We are using the function that's defined above
urls = django_docs_build_urls()
# We can do the scraping ourselves and only look for .docs-content
loader = WebBaseLoader(urls)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
splitted_documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(
splitted_documents,
embeddings,
collection_name="ask_django_docs",
persist_directory=CHROMA_DB_DIRECTORY,
)
db.persist()OpenAI API Key
First of all, since we are using OpenAI's API, we are going to need a .env with OPENAI_API_KEY inside of it. This is your OpenAI API key, that you can obtain from their developer platform.
And that's also the reason why we are using python-dotnev to automatically read thast .env file. langchain is going to look for OPENAI_API_KEY.
Document loaders
Now, the first concept that we need to deal with is the so-called document loading.
This is a fairly straightforward abstraction that takes a source of some kind (unstructured text) and turns this source into a list of documents (List[Document]), that langchain can process further.
For our example, we are using WebBaseLoader, which effectively takes a list of urls & uses bs4 internally, to get the text out of the HTML of a web page.
We can effectively do the same thing ourselves, as long as we end up with a list of documents.
Langchain supports a wide range of various document loaders.
Text splitting
After we've obtained our documents, it's time to split them in chunks.
To be fair, this is one of the most magical parts of the implementation, that certainly requires further reading.
The code snippet is what's recommended in langchain's documentation so that's what we are using.
We end up with our documents, split in chunks, ready for further processing.
Chroma and embeddings
Now, for the juicy part, we create our Chroma vector database, using OpenAI's embeddings API.
Since we don't want our Chroma to be transient (in-memory), we persist it to a specific directory, giving persist_directory.
We want to persist our database, so we can effectively ask multiple questions by running our script multiple times, without re-creating the database every time.
We also give an explicit collection_name, to avoid using langchain's default collection.
It's important to mention that this is langchain's wrapper over Chroma's client:
>>> db._client.list_collections()
[Collection(name=langchain), Collection(name=ask_django_docs)]In order to get a better understanding of what's going on, my recommendation is to check the following:
Finally, we persist our database. All of Django's documentation is now stored there, in vector format.
This is something that we need to do just once! After our database is ready, we can use it to query for answers.
In order to build our database, we can simply run the build_database function:
>>> from ask_django_docs import build_database
>>> build_database()Step 3 - Asking questions, getting answers
Here's where the most langchain magic happens.
We use the following tools:
- The 4th important feature of Indexes - Retrievers - that are an abstraction over getting relevant documents from somewhere. In our example - from Chroma.
- The chat implementation of OpenAI's GPT API.
- A ready-to-use chain called
RetrievalQAWithSourcesChain
Lets see the code & break it down after that:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
CHROMA_DB_DIRECTORY = "chroma_db/ask_django_docs"
def answer_query(query):
embeddings = OpenAIEmbeddings()
db = Chroma(
collection_name="ask_django_docs",
embedding_function=embeddings,
persist_directory=CHROMA_DB_DIRECTORY
)
chat = ChatOpenAI(temperature=0)
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=chat,
chain_type="stuff",
retriever=db.as_retriever(),
chain_type_kwargs={"verbose": True}
)
result = chain({"question": query}, return_only_outputs=True)
return resultUsing the existing Chroma database
First of all, we get a hold of our already existing Chroma database, by simply initializing it with the same collection_name, persist_directory and embedding_function as in build_database.
After that, we initialize the "llm" instance that we are going to use - ChatOpenAI
A comment on the temperature, from OpenAI's documentation -
"Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic."
That's why we are using 0 - to get the most focused & deterministic result possible.
The chain
Now, we construct a chain, that's specifically designed for "question answering over documents with sources", that's coming straight from langchain.
The retriever that we use is basically the retriever representation of our Chroma database.
Again, the retriever is a simple abstraction that can get relevant documents, from a certain source.
The interface looks like this:
class BaseRetriever(ABC):
@abstractmethod
def get_relevant_documents(self, query: str) -> List[Document]:
"""Get documents relevant for a query.
Args:
query: string to find relevant documents for
Returns:
List of relevant documents
"""Something that initially threw me off was chain_type="stuff", which, turns out is not a random placeholder, but rather a valid value. More detailed explanation around different chain types can be found here.
Additionally, we pass {"verbose": True}, so we can see the final prompt that's going to be sent to ChatGPT.
Seeing the final prompt can really help you understand what langchain is trying to do, so the result can be meaningful. And yes, it does include some random stuff, as an additional context for the LLM.
This text caught me by surprise and I ended up looking closely at what I've scraped, because it was really non-Django related.
We are effectively "prompt engineering" for a factual response.
And with that - we have our little Python application ready 🎉
We can finish it off with the following:
def main():
query = input("Ask a question related to Django: ")
result = answer_query(query)
print(result["answer"])
print(result["sources"])
if __name__ == "__main__":
main()
The code snippets and examples are based on the following documents:
- https://python.langchain.com/en/latest/use_cases/question_answering.html
- https://docs.langchain.com/docs/use-cases/qa-docs
- https://python.langchain.com/en/latest/modules/chains/index_examples/question_answering.html
- https://python.langchain.com/en/latest/modules/chains/index_examples/qa_with_sources.html
- https://python.langchain.com/en/latest/modules/chains/index_examples/vector_db_qa.html
- https://python.langchain.com/en/latest/modules/chains/index_examples/vector_db_qa_with_sources.html
Where do we go from here?
Of course, this little Python app is nowhere near production ready.
The purpose of this blog post is to get our hands dirty and fiddle with new concepts.
One can build the same thing without langchain. Where langchain helps us here is the following:
- We get to a working example much faster.
- Once we have a working example, we can start iterating and trying out different things.
- We can start peeling back the layers of abstraction, thinking about why they are there.
- We can see the actual implementation, understanding the more fundamental concepts.
As potential next steps, I'd do the following:
- Do the same thing, using only OpenAI's Python SDK - https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb
- Explore how to work with Chroma in a client / server manner - https://docs.trychroma.com/usage-guide#running-chroma-in-clientserver-mode
- Deploy Chroma somewhere - https://docs.trychroma.com/deployment
- Explore how to store the embeddings in PostgreSQL- https://supabase.com/blog/openai-embeddings-postgres-vector
- Explore how to store the embeddings in Redis - https://redis.io/docs/stack/search/reference/vectors/
- Take only the Django documentation content, instead of the entire HTML page (scrape and look for
.docs-content). - Fiddle with different text splitting options.
- Deploy this somewhere and give it a simple user interface (potentially Vercel).
By being curious about the new AI tools & building a very simple proof of concept, we can iteratively expand our knowledge and gain new ideas & new capabilities.